Use AI to Reduce Cost of Research

My Role
- Qualitative Research Collection
- Study Design
- Coordination with the data science team
Summary
The goal of this project was to demonstrate the capabilities of extractive summarization for making it easier for UX researchers to analyze feedback through summarization of transcripts into several key sentences that may be of importance.
Problem
It is expensive to do post-interview analysis.
How can we speed up research analysis and allow research to collect more findings instead of analyzing?
Solution Overview
- Defined the manual steps of analysis
- Identified a proof-of-concept - single participant overview analysis
- Worked with the data science team
- Developed personally-identifiable data scrubbing tool
- Developed extractive summaries
- Reviewed outputs, and identified most promising technology, Gensim Extraction
Process
- Count Lengths for each string summary
- Gensim Extractive Summarization
- Spacy Approach
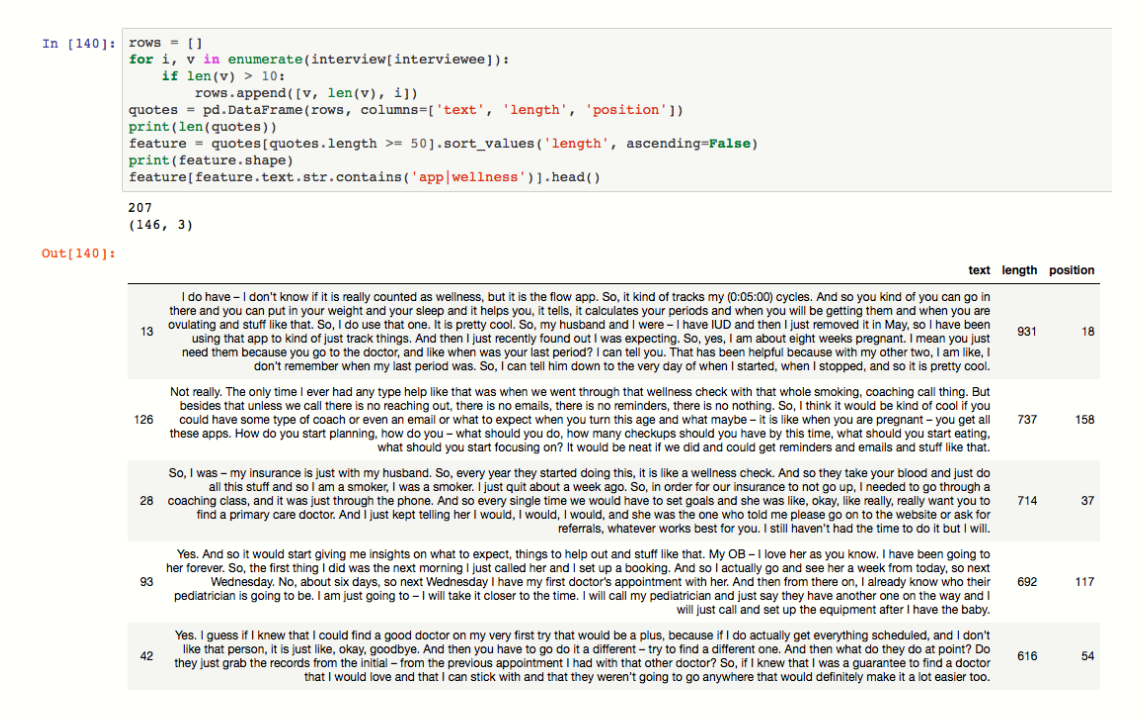
Count Length for Each String Summary
We initially used a naive approach and count lengths of each string. The idea here is that the longer the quote is the more likely that it is significant. We also filter out strings to only include those that mention relevant terms, like “app”, “wellness”, etc...
Gensim Extractive Summarization
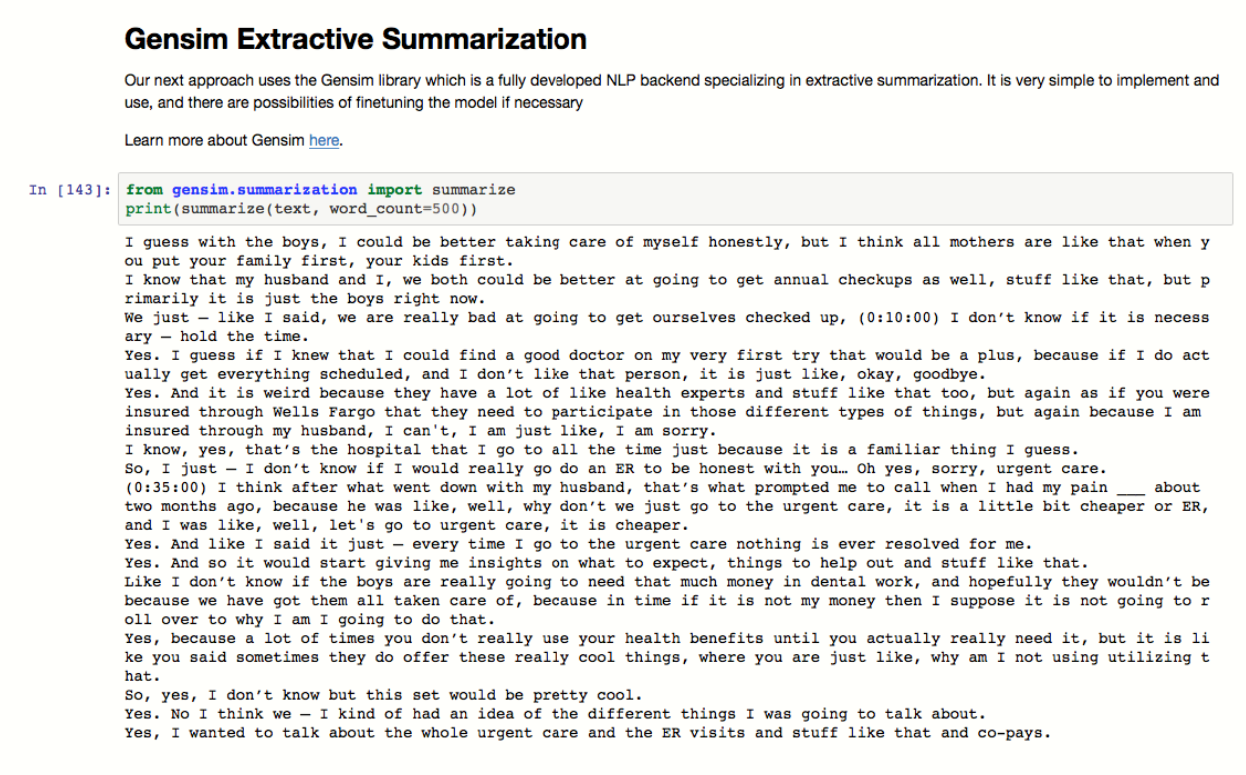
Our next approach uses the Gensim library which is a fully developed NLP backend specializing in extractive summarization. It is very simple to implement and use, and there are possibilities of fine-tuning the model if necessary. Learn more about Gensim here.
Spacy Approach
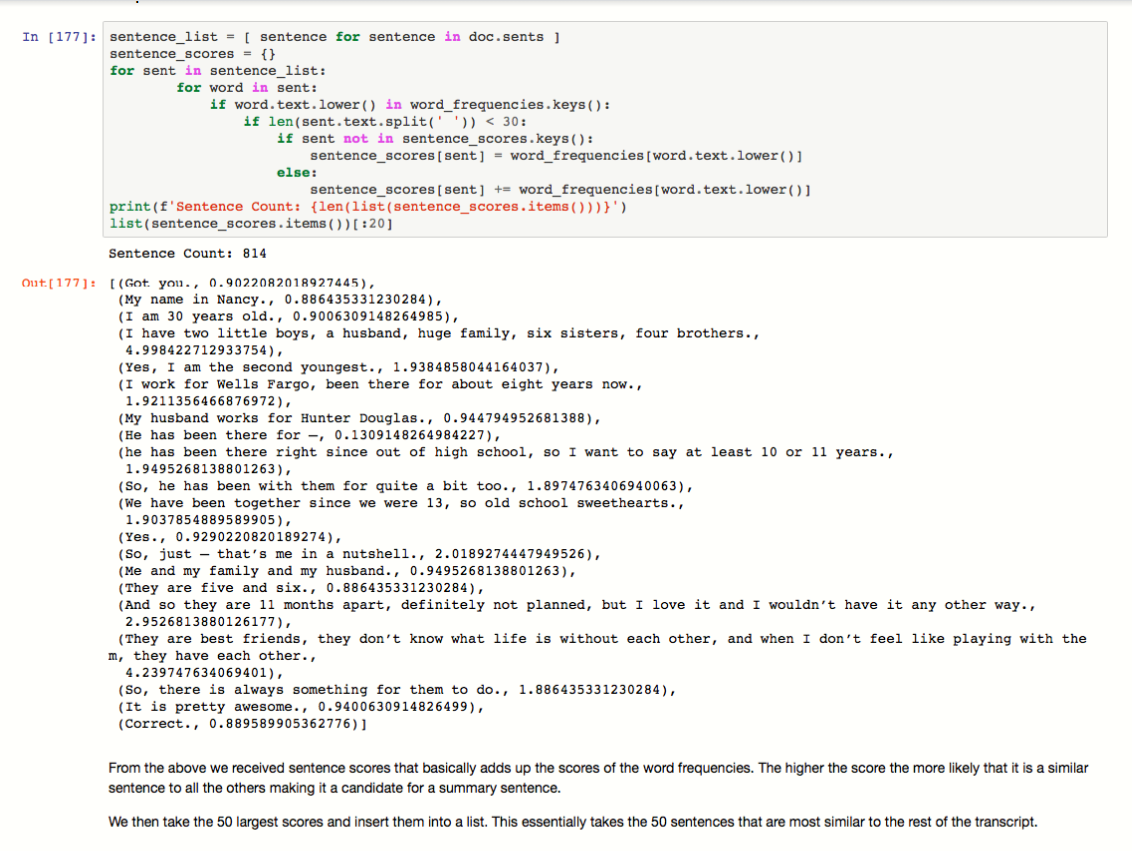
Our last approach was to use Spacy. Spacy does not come with a built in summary function, so we must make an inference based on word frequencies and scoring the frequency of words. We then extend that to sentences to generate our summarization. The idea is that if a sentence is related or similar to a large number of other sentences then it is a good candidate to summarize those sentences. We received sentence scores that basically adds up the scores of the word frequencies. The higher the score the more likely that it is a similar sentence to all the others making it a candidate for a summary sentence. We then take the 50 largest scores and insert them into a list. This essentially takes the 50 sentences that are most similar to the rest of the transcript.
Results
- Confirmed the hypothesis that personally-identifiable information could be scrubbed using NLP.
- Gensim Extractive Summarization would be valuable when we conduct participant summary (field notes) documentation.
- Even without fine-tuning, we estimate that this method can reduce the cost of analysis by 50%.
- The research teams spend approximately 40 hours per study on the field analysis document, this would save 20 hours per study.
- The next step is to apply a similar summarization technique to answers across multiple participants. If this can reduce the cost of analysis by a similar amount, this will save 100's of hours per study.
